Lorsque l'on commence un projet de cartographie, se pose la question du périmètre de données. De prime abord il semble souvent essentiel de tout cartographier. Comment tirer de la valeur d'une cartographie incomplète? Cependant cette approche rencontre aussi différentes limites : charge de création et maintenance, intérêt de l'information au regard du cas d'usage et des populations utilisatrices...
Si tout n'a pas vocation à être remonté (au moins dans un premier temps) se pose alors la question de l'identification des données devant être remontées. Nous utilisons pour cela la méthodologie des Key Data Elements (KDE ou éléments de données clés).
Qu'est ce que les KDE ?
Les KDE sont des données
- Ayant un impact significatif sur une activité ou bien un ou des processus analytiques.
- et/ou qui s'étendent sur plusieurs systèmes et rapports,
- et/ou qui sont utilisés par la direction pour prendre des décisions critiques.
Les KDE sont des éléments pour lesquels tout problème de qualité des données a un impact sur des décisions cruciales. Elles nécessitent donc une attention particulière. Il s'agit donc de données bien spécifiques. Tous les éléments d'un système ou d'un rapport ne sont pas considérés comme des KDE.
Pourquoi les identifier ?
Comme nous l'avons vu plus haut, il est non seulement difficile mais également chronophage de cataloguer toutes les données de l'organisation. Il faut donc être en mesure de limiter le périmètre. La création d'un cas d'usage est une bonne première étape pour limiter le périmètre. Cette approche peut être complété par l'approche par données clés. Ainsi identifier ces données clés nous permettra de concentrer nos actions sur les données vraiment importantes pour l'organisation ou le public visé par le cas d'usage.
Comment les identifier ?
Pour identifier les données clés, Il faut réaliser un inventaire des données disponibles et pour chacune mesurer sa criticité. Pour cela nous proposons d'utiliser le cadre de notation suivant :
| Questions | Valeur |
| Est-ce que la donnée à été identifiée comme une KDE par un expert du domaine ? | 10 |
| Est-ce que la donnée est nécessaire pour effectuer des liens entre systèmes ? | 4 |
| Est-ce que la donnée est nécéssaire pour construire un reporting ou prendre des décisions ? | 4 |
| Est-ce que la qualité de cette donnée va impacter des clients ? | 4 |
| Est-ce que la donnée est utilisée dans de nombreux rapports ? | 2 |
| Est-ce que la donnée est identifiée comme une source pour une autre KDE ? | 2 |
| Est-ce que la qualité de la donnée aura un impact direct sur la modélisation des données ? | 2 |
| Est-ce que la donnée à été identifiée par un organisme extérieure ? | 2 |
| Est-ce que la donnée est utilisée à des fins de segmentation ? | 2 |
| Est-ce que la donnée est constituée de données personnelles ? | 2 |
Il suffit alors d'ajouter toutes les "valeurs" obtenues lorsqu'une donnée répond à une ou plusieurs conditions.
Celui-ci peut bien sûr être complété ou amendé selon les contraintes de l'organisation.
Toutes les données recevant un score supérieur à 10 sont alors des données KDE pour lesquelles il faudra mener des actions de documentation prioritaire. Il est tout à fait possible de classifier encore plus finement les KDE grâce au score obtenu. par exemple
| Score obtenu | Priorité |
| [10 - 14] | 3 |
| [15 - 17] | 2 |
| [18 - 20] | 1 |
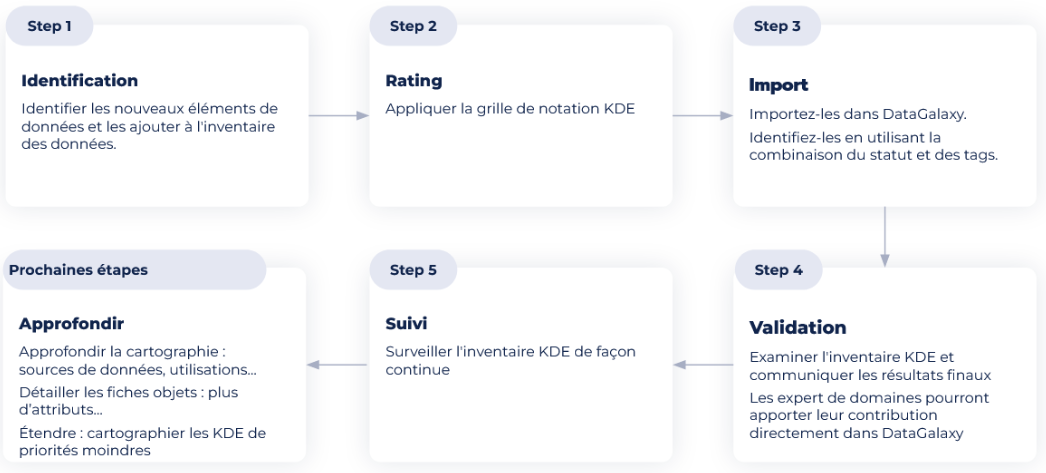
Comment appliquer cette méthodologie?
L'évaluation des KDE se fait grâce à une méthode itérative et incrémentale en 5 étapes.