Le connecteur permet d'importer les métadonnées de vos systèmes de traitement de données existants dans la plateforme DataGalaxy. Dans cet article, nous vous expliquons quelles métadonnées seront importées dans la plateforme et comment configurer ces imports.
Pour mettre en application les éléments présentés dans cet article, il vous faudra télécharger le connecteur et les plugins associés (voir cet article). Les plugins concernés sont ceux de type Traitement qui permettent de faire uniquement un export CSV.
Le fonctionnement du connecteur en mode interface graphique est expliqué en détail dans cet article
Le cas échéant, des articles de documentation spécifiques à chaque technologie et plugin peuvent être disponibles afin de détailler leurs particularités.
Correspondances entre les objets des systèmes sources et le métamodèle DataGalaxy
Le tableau suivant décrit les correspondances qui seront appliquées par défaut lors de l'import de vos traitements dans DataGalaxy
| Système source | Objet DataGalaxy | Commentaires |
|---|---|---|
| Dossier | Flux de données | Les flux de données vont être utilisés pour représenter l'organisation des traitements dans le système source et les regrouper |
| Traitement | Traitement | |
| Tables et colonnes en entrée de traitement | Entrées de traitement | |
| Tables et colonnes en sortie de traitement | Sorties de traitement | |
| Etape de traitement | Etape de traitement | En fonction du connecteur, ces étapes de traitement ne sont pas forcément créées lors d'un import |
Avant d'effectuer l'import d'un traitement, il faudra vous assurer au préalable que toutes les tables et colonnes exploitées par ce dernier ont été déclarées dans le module dictionnaire de DataGalaxy. En effet les plugins de traitement viennent alimenter uniquement le module Traitement, et ne vont pas créer les sources utilisées par les traitements dans le module Dictionnaire de DataGalaxy
Connexion à un référentiel de traitement stocké dans une base de données
Lorsque la définition des traitements est stockée dans une base de données, DataGalaxy vous propose de récupérer directement les informations liées dans ces référentiels. Auquel cas la connexion s'effectue à l'aide d'un driver JDBC qu'il faudra installer au préalable (il est aussi possible de faire appel à un driver JDBC embarqué dans un plugin le cas échéant).
Pour ce type de plugin, le driver JDBC devra avoir été préalable copié dans le répertoire /lib du connecteur pour pouvoir être utilisé dans une chaîne de connexion
Un exemple ci dessous avec le plugin OTIC (ex-Genio), l'écran vous propose d'entrer les informations de connexion au format JDBC (des exemples sont généralement disponibles sur le site où vous avez téléchargé le driver) : 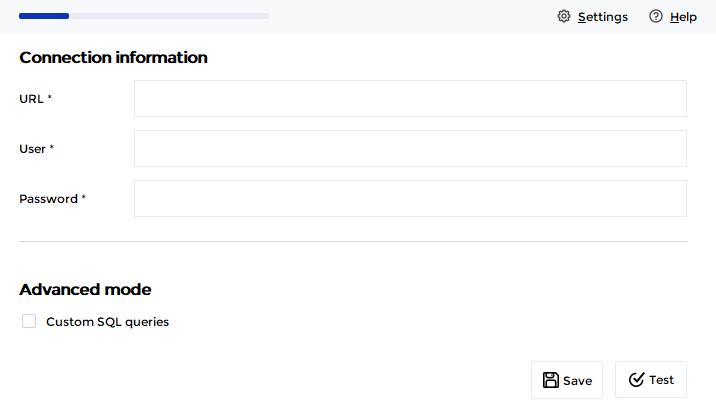
Le mode avancé vous permet de référencer un fichier contenant les requêtes à exécuter pour récupérer les métadonnées. Des exemples de fichiers sont disponibles dans le dossier /queries/processing du connecteur
Ne pas modifier les fichiers déjà présents dans ce dossier qui peuvent utilisés par le connecteur. Effectuez une copie pour créer vos propres jeux de requêtes
Lorsque vous enregistrez les informations de connexion, le chemin vers le fichier de requêtes personnalisées sera enregistré dans la connexion
Utilisation d'un fichier de mapping pour gérer les correspondances d'objets
Comme expliqué dans le paragraphe concernant les correspondances, les sources utilisées en entrée et en sortie des traitements doivent avoir été déclarées au préalable dans DataGalaxy. Néanmoins il est fort probable que cette définition diffère de celle connue par vos systèmes de traitements, à partir desquels vous êtes en train d'effectuer un import de métadonnées. Un exemple ci dessous avec le plugin SSIS :
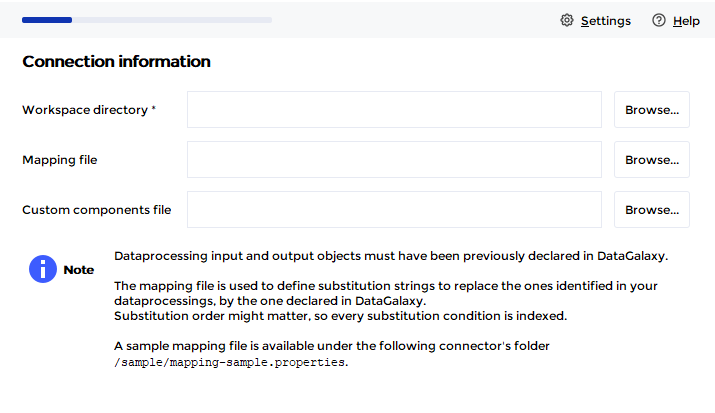
Ce fichier est donc optionnel dans la procédure d'export du connecteur, mais souvent indispensable pour réussir à importer les fichiers CSV générés dans la plateforme.
Le fichier de mapping permet de définir des chaînes de caractères de substitution à utiliser pour remplacer celles des sources identifiées dans vos traitements, par la chaîne de caractère de la source telle qu'elle est définie dans DataGalaxy. L'ordre de remplacement pouvant avoir de l'importance, chaque condition de remplacement est indexée pour que vous puissiez maîtriser l'application de ces règles.
Un exemple de fichier de mapping est disponible dans le fichier /sample/mapping-sample.properties du connecteur, ci dessous un extrait de ce qu'il peut contenir
# Sample mapping file
#
# Keys must begin with a positive integer.
# It guarantees that "find and replace" operations will be applied in this specific order.
# Each operation must have a "find" and a "replace" key. For instance:
#
# 1.find=old
# 2.replace=new
#
# Find is case-sensitive, "tHDFSConfiguration" won't match "thdfsconfiguration".
# Backslash character must be escaped.
# File must be encoded in ISO-8859-1.
# 1. Replace "\tHDFSConfiguration_1\env\project" by "\pull"
1.find=\\tHDFSConfiguration_1\\/env/project
1.replace=\\pull
# 2. Then replace "/" by "\"
2.find=/
2.replace=\\
# 3. Then replace "${INCOMING_DIRECTORY}" by "incoming"
3.find=${INCOMING_DIRECTORY}
3.replace=incoming
# 4. Then replace "" (empty) by "\push"
4.find=
4.replace=\\push
# 5. Then replace "${ENVIRONMENT}" by "" (empty)
5.find=${ENVIRONMENT}
5.replace=
a